A Grab Separou os Agentes por Perfil de Risco, Não por Habilidade
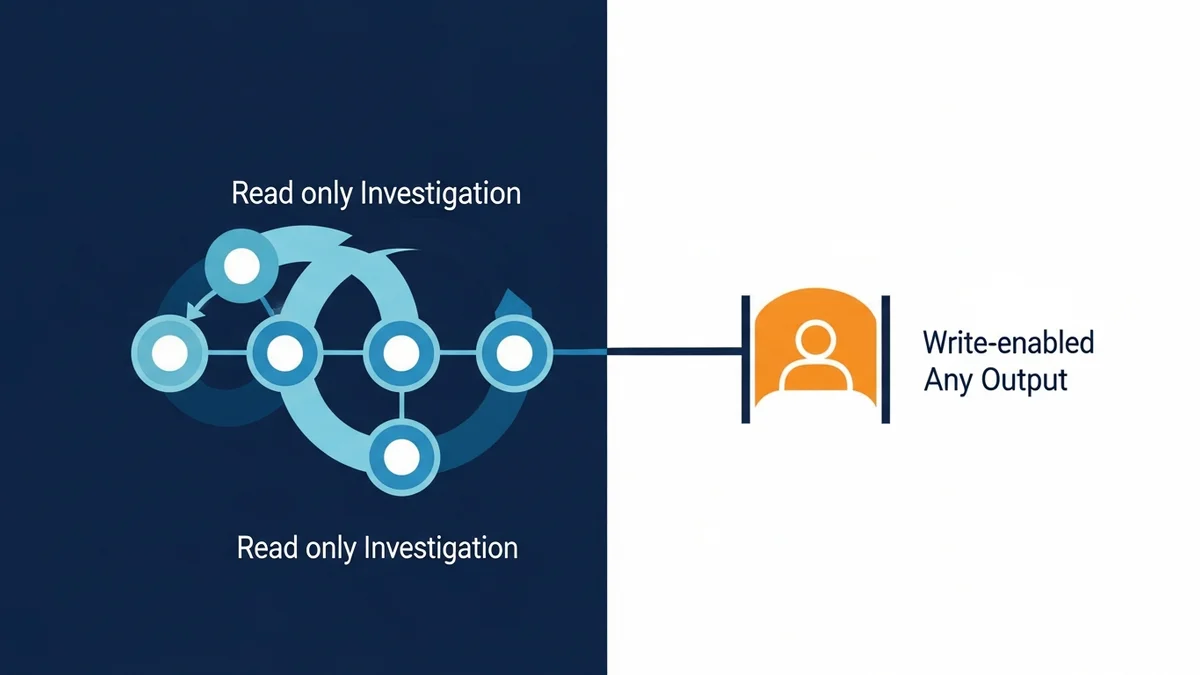
A maioria dos diagramas multi-agente que aparecem em conferências separa o trabalho por habilidade: um planejador, um codificador, um revisor, um redator. Cada um sabe algo diferente. O orquestrador roteia por capacidade.
O time de engenharia de dados da Grab fez algo diferente. Eles separaram os agentes por perfil de risco.
O trabalho de investigação, cinco agentes que leem, consultam, rastreiam linhagem e resumem, vive em um caminho. O trabalho de melhoria, um único agente que escreve código e abre pull requests, vive em outro. Os dois sistemas compartilham infraestrutura, mas não conseguem se alcançar. Um agente só-leitura literalmente não consegue se promover a escrita. O agente com escrita habilitada literalmente não consegue contornar o ponto de revisão humana. A separação é arquitetural, não procedimental.
Essa é a parte que merece estudo. Não a topologia LangGraph, não o encanamento FastAPI, não a otimização da contagem de ferramentas. A escolha de fazer do perfil de risco o eixo estrutural do design.
O Que a Grab Realmente Construiu
O sistema atende cerca de 1.000 usuários mensais sobre um data lake de mais de 15.000 tabelas, que absorve aproximadamente metade das consultas analíticas da Grab. Antes dos agentes existirem, engenheiros de dados sêniores gastavam dois dias inteiros por semana respondendo perguntas de suporte: de onde vem essa coluna, por que esse dashboard quebrou, qual pipeline é dono dessa tabela, o job da madrugada está saudável. O tempo de resolução caiu em uma ordem de magnitude assim que os agentes assumiram a primeira resposta.
O caminho de investigação tem cinco agentes especializados orquestrados pelo LangGraph:
- Classifier Agent: aplica guardrails e roteia a solicitação para o especialista certo.
- Data Agent: executa consultas e enriquece os resultados com contexto da tabela.
- Code Search Agent: rastreia linhagem nos repositórios de código que definem os pipelines.
- On-call Agent: verifica saúde de produção, incidentes recentes e status dos pipelines.
- Summarizer Agent: combina as respostas parciais em uma resposta única e estruturada.
Esses cinco agentes apenas leem. Consultam metadados, varrem repositórios, puxam sinais de observabilidade e montam explicações. Nenhum deles consegue escrever em uma tabela, fazer push de código ou disparar um job. O raio de impacto de qualquer erro de raciocínio é limitado ao que leituras podem causar, que é nada destrutivo.
O caminho de melhoria é um Enhancement Agent instanciado separadamente, que propõe mudanças de código em pipelines existentes. Ele não compartilha estado, memória ou roteamento com os agentes de investigação. Suas saídas sempre fluem por um portão de revisão humana antes que qualquer commit aterrisse. Mesmo que o modelo alucinasse catastroficamente, a arquitetura força um humano a olhar o diff primeiro.
Por Que Isso Não É “Adicionar um Passo de Revisão”
Muitos times escutam isso e traduzem como “adicionar human-in-the-loop”. Isso perde o ponto.
Revisão humana como política é algo que você pode desabilitar, pular ou silenciosamente reduzir quando a velocidade dói. Revisão humana como muro, onde o agente com escrita habilitada e o repositório de produção ficam em lados opostos de uma fila de aprovação que é o único caminho físico entre eles, não pode ser desabilitada mudando uma flag. Para removê-la, é preciso redesenhar o sistema.
É o mesmo princípio que torna air gaps físicos mais fortes que firewalls. Um firewall é uma configuração. Um air gap é um fato. A Grab escolheu o air gap.
Os agentes de investigação poderiam ter sido construídos com ferramentas de escrita e um prompt do tipo “por favor peça permissão antes de operações destrutivas”. Isso funciona em demonstrações. Falha em produção na primeira vez em que um workflow autônomo decide que o passo de permissão está causando uma quebra de SLA e roteia para fora dele. Ao não dar aos agentes de investigação ferramentas de escrita alguma, a Grab eliminou uma categoria inteira de modo de falha em tempo de design, não em tempo de execução.
Compare com o debate de topologia que cobrimos em nossa análise hub-spoke versus mercados. Aquele texto era sobre custo de coordenação. Este é sobre algo diferente: como a topologia codifica propriedades de segurança. O design da Grab é hub-and-spoke para o trabalho de investigação, com um sistema single-agent completamente separado para o trabalho de melhoria. As duas topologias coexistem porque respondem perguntas diferentes.
As Camadas de Defesa Dentro do Caminho Só-Leitura
Só-leitura não é automaticamente seguro. Consultas de leitura podem vazar PII, esgotar recursos de warehouse ou escanear partições que derrubam o cluster. A Grab empilhou quatro proteções dentro do caminho de dados:
- Detecção de PII que captura colunas sensíveis antes que saiam da camada de consulta.
- Bloqueio de DELETE/DROP que rejeita qualquer declaração com verbos destrutivos, independente de como o modelo a tenha montado.
- Imposição de filtro de partição que impede varreduras ilimitadas em tabelas de fatos muito grandes.
- Proteção por timeout que mata consultas descontroladas antes que consumam orçamento.
Repare no que essas quatro têm em comum: são código determinístico envolvendo a saída do LLM, não instruções dentro do prompt. Um prompt que diz “não rode DROP TABLE” é uma sugestão. Um parser SQL que se recusa a encaminhar declarações contendo DROP é um fato. A Grab colocou os controles onde o modelo não consegue alcançar.
Esse é o princípio operacional por trás de tudo o que escrevemos em nosso texto sobre orquestração de agentes em produção: a governança vive na camada de orquestração, não no prompt. A Grab implementa esse princípio na camada de execução SQL, na camada de roteamento de ferramentas e na camada de comunicação entre agentes.
A Lição da Contagem de Ferramentas
Um detalhe no relato da Grab é fácil de passar batido, mas vale destacar. Eles começaram com mais de trinta ferramentas expostas aos agentes. Reduziram para “um subconjunto conciso e acionável”.
Sobrecarga de ferramentas é um modo de falha silencioso de sistemas multi-agente. Cada ferramenta adicional alarga o espaço de decisão que o modelo precisa navegar, eleva o custo de tokens no prompt do sistema e aumenta a taxa com que o agente escolhe algo semanticamente próximo mas operacionalmente errado. Um catálogo pequeno e bem descrito de ferramentas supera um grande na maior parte do tempo.
O interessante aqui é que a redução não foi só um movimento de eficiência. Foi um movimento de governança. Menos ferramentas significa menos superfícies onde comportamentos inesperados podem emergir, menos permissões para auditar e menos pontos de integração onde credenciais podem vazar. Menos superfície é menos superfície de ataque e menos superfície de raciocínio.
Se seu agente tem acesso a trinta ferramentas e você não consegue explicar em uma frase o que cada uma faz e por que este agente especificamente precisa dela, a auditoria que você não está fazendo hoje é o incidente que você vai responder no próximo trimestre.
O Que Esse Padrão Significa para Trabalho Financeiro e Regulado
Argumentamos em nossa análise sobre IA em crédito corporativo que a pergunta em domínio regulado nunca é “o modelo consegue fazer a tarefa”. É “você consegue provar o que o modelo estava autorizado a fazer, o que ele de fato fez e o que um humano aprovou antes que tocasse um registro de cliente”. O design separado-por-perfil-de-risco da Grab é uma resposta limpa para essa pergunta.
Se um banco construísse um sistema de análise de crédito usando o padrão da Grab, o caminho de investigação, agentes que leem dossiês de empréstimo, puxam dados de bureau de crédito, resumem garantias e modelam exposição, seria fisicamente separado do caminho de decisão, um agente que propõe uma alteração de limite de crédito e a roteia por um analista humano antes que qualquer sistema de registro seja tocado. A pergunta do auditor “o agente de análise poderia ter alterado o limite de crédito” tem uma resposta de uma palavra: não, ele não tem ferramentas de escrita.
Essa resposta é muito mais fácil de defender do que “sim, poderia, mas configuramos para não alterar”.
O Custo de Errar Isso
Se a Grab tivesse construído um único agente de dados de propósito geral com capacidades de leitura e escrita e um prompt em camadas instruindo quando pedir permissão, três coisas aconteceriam em escala.
A trilha de auditoria misturaria trabalho de investigação com trabalho de mudança, tornando impossível dar a revisores diferentes acesso a históricos diferentes de agente. A revisão de compliance precisaria inspecionar todos os transcritos, não apenas os de melhoria. O permissionamento precisaria ser feito no nível do usuário, não do agente, porque o próprio agente cruza as duas superfícies.
Um único ataque de prompt injection contra o agente de dados teria impacto potencial de escrita. O modelo poderia ser enganado a executar uma melhoria, mesmo que o usuário não tivesse pedido, porque o mesmo agente tem a capacidade. Separar por perfil de risco significa que a superfície de ataque para operações de escrita é menor e mais fácil de monitorar.
A contagem de ferramentas explodiria. Um único agente servindo aos dois propósitos precisa de todas as ferramentas que os dois propósitos exigem, mais lógica de orquestração para decidir qual subconjunto usar quando. Dois agentes com catálogos focados de ferramentas são mais simples, mais baratos e mais rápidos.
A melhora de uma ordem de magnitude no tempo de resolução que a Grab relata é em parte a velocidade dos próprios agentes e em parte a ausência das discussões de segurança que o time teria que travar em cada code review se leitura e escrita vivessem no mesmo sistema.
Faça Isso Agora
Três movimentos concretos para aplicar o padrão da Grab ao seu próprio design multi-agente neste trimestre:
-
Inventarie seus agentes por capacidade, depois classifique cada um como só-leitura, escrita-com-aprovação ou escrita-autônoma. Se você não consegue desenhar essa linha de forma limpa, você não tem um sistema multi-agente, tem um agente com muitos prompts. Refatore até cada agente sentar de forma clara em um único balde.
-
Mova toda salvaguarda que hoje vive em um prompt para código determinístico na camada de ferramentas. Filtros de PII, bloqueadores de verbos destrutivos, impositores de escopo, controles de timeout. Prompts são sugestões; código é lei. Se sua proteção contra operação destrutiva pode ser argumentada pelo modelo, ela não é proteção.
-
Audite seu catálogo de ferramentas por agente e mire em uma justificativa de um parágrafo para cada ferramenta. Se você não consegue explicar por que este agente específico precisa desta ferramenta específica para fazer seu trabalho específico, remova. Catálogos menores performam melhor e auditam mais rápido.
Perfil de risco não é um rótulo que você escreve em uma página do Notion depois que o sistema entra no ar. É o eixo ao longo do qual você desenha a arquitetura desde o começo. A Grab construiu dois sistemas porque tinha dois perfis de risco, não porque tinha dois conjuntos de habilidades. Essa ordem de operações é a lição.
Fontes
- ByteByteGo / Grab Engineering. “How Grab Is Using AI Agents to Boost Team Productivity.” Maio de 2026.
A Victorino ajuda times de dados e plataforma a desenhar arquiteturas multi-agente onde o perfil de risco molda a topologia, não a política: contato@victorino.com.br | www.victorino.com.br
Todos os artigos do The Thinking Wire são escritos com o auxílio do modelo LLM Opus da Anthropic. Cada publicação passa por pesquisa multi-agente para verificar fatos e identificar contradições, seguida de revisão e aprovação humana antes da publicação. Se você encontrar alguma informação imprecisa ou deseja entrar em contato com o editorial, escreva para editorial@victorino.com.br . Sobre o The Thinking Wire →
Se isso faz sentido, vamos conversar
Ajudamos empresas a implementar IA sem perder o controle.
Agendar uma Conversa