Alta Capacidade de Raciocínio Cita Outra Web. Sua Visibilidade em IA Bifurcou.
Kevin Indig rodou 100 prompts em 20 jornadas de compra e quatro verticais através do GPT 5.2 em duas configurações de raciocínio: mínima e alta. Os dados, publicados em sua edição de maio de 2026 do Growth Memo “Reasoning Lift: What Happens to AI Visibility When AI Thinks Harder”, deveriam mudar como times de marketing e growth pensam medição de busca por IA.
O resultado principal não é que raciocínio alto cita mais fontes. Isso era esperado. O resultado principal é que raciocínio alto cita uma web diferente.
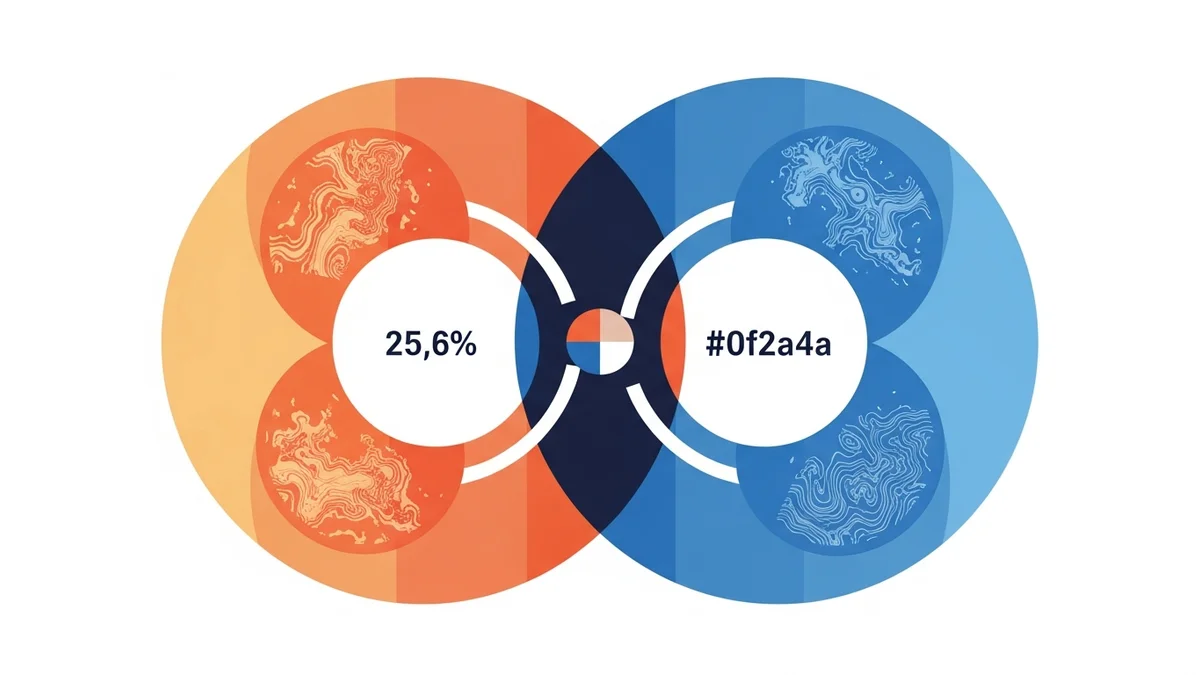
Apenas 25,6% dos domínios citados se sobrepõem entre os dois modos. Noventa e nove domínios aparecem exclusivamente quando o raciocínio está alto. As buscas internas ramificadas (fan-out) multiplicam 4,6x. A taxa de citação sobe de 50% para 68%. A média de fontes por resposta vai de 2,6 para 4,5.
Mesmo modelo. Mesmos prompts. Dois mercados de informação diferentes.
A bifurcação é operacional, não acadêmica
A maioria das ferramentas de visibilidade em IA hoje agrega. Roda prompts, coleta citações e reporta um número único: share of voice, taxa de citação, índice de presença. Essa agregação fazia sentido quando as respostas de LLM eram estruturalmente similares. Para de fazer sentido no momento em que o mesmo modelo se comporta como dois sistemas de busca diferentes dependendo de um parâmetro de execução.
Os dados de Indig forçam a pergunta: qual versão do GPT 5.2 seus clientes realmente usam? Se metade dos compradores roda queries em raciocínio mínimo (rápido, barato, default em várias superfícies de produto) e a outra metade roda queries em raciocínio alto (mais lento, mais profundo, cada vez mais o default para compras consideradas), então uma métrica única de visibilidade é a média de duas populações que podem nem compartilhar a mesma shortlist de marcas.
Mediar entre elas não é medição. É camuflagem.
Onde a bifurcação bate mais forte
O comportamento de fan-out é o mecanismo. Sob raciocínio mínimo, o GPT 5.2 faz em média um punhado de buscas internas antes de responder. Sob raciocínio alto, faz 4,6x mais. O efeito composto aparece de forma mais dramática no meio e no final do funil.
Queries de estágio de comparação vão de 5,5 buscas fan-out (mínimo) para 24 (alto). Queries de estágio de seleção vão de 2,6 para 15,4. Esses são exatamente os estágios da jornada de compra onde citação de marca importa mais: quando alguém está montando shortlist de fornecedores, quando alguém está decidindo.
A implicação: marcas otimizadas para queries de awareness de topo de funil podem parecer bem em dashboards agregados de visibilidade enquanto estão completamente ausentes do conjunto de citações que usuários de raciocínio alto veem durante avaliação. O mercado de estágio de decisão é o que converte. Também é o mais provável de ficar escondido pela média.
Por que isso não é “mais um padrão vertical”
Alguns analistas de visibilidade em IA vão fazer pattern-match disso com achados anteriores de variância vertical. Esse pattern-match está errado.
Variância vertical diz que indústrias diferentes são citadas de formas diferentes. Isso é verdade e já escrevemos sobre. Bifurcação por modo de raciocínio diz algo mais estranho: dentro da mesma vertical, dentro do mesmo prompt, dentro do mesmo modelo, o pool de fontes pode ser quase completamente diferente dependendo de um único botão de execução. A variância não está entre mercados. Está dentro do mesmo mercado.
Também não é o mesmo problema que acoplamento de plataformas (quais plataformas citam quais fontes) ou o déficit de fan-out (a defasagem de 27% no ranqueamento do Google para queries fan-out que cobrimos no ponto cego do fan-out do ChatGPT). Esses problemas existem entre sistemas. Bifurcação de raciocínio existe dentro de um.
O que os dashboards agregados estão escondendo
Se você reporta qualquer um dos itens abaixo como número único, agora está reportando média de duas populações:
- Share of voice entre assistentes de IA
- Taxa de citação por marca
- Score de autoridade de domínio para busca por IA
- Presença de competidores no texto da resposta
- Cobertura de tópicos por categoria de query
Nenhum desses está errado. Estão incompletos. A mesma marca pode ter 70% de taxa de citação em raciocínio mínimo e 30% em raciocínio alto, ou o inverso, e a média reportada não diz nada acionável.
A metodologia de Indig usou a API do AI Visibility Toolkit da Semrush para rodar prompts pareados em cada configuração de raciocínio. Esse design pareado é a disciplina que o resto do mercado ainda não adotou. Até adotar, a maioria dos dashboards está medindo uma média fantasma.
A nova unidade de governança
Já argumentamos que AEO já foi comoditizado e que os KPIs reais para busca por IA exigem tratar visibilidade como disciplina de medição, não como métrica. Os dados de Indig estendem esse argumento.
Modo de raciocínio agora é uma dimensão de governança. Tratar “visibilidade em IA” como objeto único é o equivalente a tratar “visibilidade em busca” como objeto único quando desktop e mobile divergiram. Os times que separaram métricas desktop versus mobile em 2014 viram sinal real. Os times que continuaram agregando viram ruído.
Mesmo arco, linha do tempo mais rápida. Os times que segmentarem por modo de raciocínio em 2026 vão ver o que os competidores perdem.
Faça isto agora
Três movimentos concretos para líderes de marketing e growth neste trimestre:
Rode novamente seus 20 prompts prioritários nas duas configurações de raciocínio e compare os domínios citados. Não a contagem de citações. Os conjuntos de domínios citados. Se a sobreposição estiver abaixo de 50%, seu dashboard agregado está mediando dois mercados. Você precisa de dois dashboards.
Segmente seus KPIs de visibilidade em IA por intensidade de raciocínio, não só por assistente. Reportar ChatGPT versus Perplexity versus Gemini é o básico. A próxima camada é reportar pools de citação de raciocínio baixo versus alto dentro de cada assistente. O delta de fan-out é onde o sinal de estágio de decisão mora.
Audite sua presença na shortlist no estágio de seleção sob raciocínio alto. Essa é a camada mais próxima da conversão. Se você aparece em 15,4 buscas fan-out durante seleção e seu competidor aparece em 24, você está perdendo o conjunto de consideração antes do comprador falar com vendas. Presença na shortlist no estágio de seleção sob raciocínio alto é o indicador-líder mais próximo de pipeline gerado por busca por IA que existe hoje.
As marcas que governarem esses dois mercados como dois mercados vão compor. As marcas que continuarem agregando vão continuar se perguntando por que o dashboard diz uma coisa e o pipeline diz outra.
Fontes
- Growth Memo (Kevin Indig). “Reasoning Lift: What Happens to AI Visibility When AI Thinks Harder.” Maio de 2026.
A Victorino ajuda times de marketing e growth a governar a visibilidade em busca por IA como disciplina de medição, não como métrica: contato@victorino.com.br | www.victorino.com.br
Todos os artigos do The Thinking Wire são escritos com o auxílio do modelo LLM Opus da Anthropic. Cada publicação passa por pesquisa multi-agente para verificar fatos e identificar contradições, seguida de revisão e aprovação humana antes da publicação. Se você encontrar alguma informação imprecisa ou deseja entrar em contato com o editorial, escreva para editorial@victorino.com.br . Sobre o The Thinking Wire →
Se isso faz sentido, vamos conversar
Ajudamos empresas a implementar IA sem perder o controle.
Agendar uma Conversa